객체지향 프로그래밍(OOP, Object Oriented Programming)
컴퓨터 프로그래밍의 관점에서 보면 일련의 명령어들의 나열을 통해 컴퓨터에게 말을 건네는 절차적 프로그래밍 방식과는 다르게, 객체지향적 프로그래밍은 프로그래밍에서 필요한 데이터를 한 데 모아 추상화시켜 상태와 행위를 가진 객체를 만들고 그 객체들 간의 협력과 유기적인 상호작용을 통해 특정 기능을 구성하는 프로그래밍 방법론을 지칭한다.
즉, 객체지향프로그래밍은 실제 사물의 속성과 기능을 분석한 후에 이것을 프로그래밍의 변수와 함수로 정의함으로 실제 세계를 최대한 컴퓨터 프로그래밍에 반영하고자 하는 것이다.
객체들은 하나의 완전하고 독립적인 기능을 가지기 때문에, 그 자체로 유용하고 손쉽게 재활용 할 수 있습니다. 따라서 기존 코드를 활용해서 새로운 코드를 상대적으로 손쉽게 작성할 수 있고, 코드 간의 관계 설정을 통해 적은 노력으로도 쉽게 코드를 변경할 수 있게 된다.
결과적으로 프로그래밍 설계의 측면에서 보면 프로그램 개발 및 유지 보수에 드는 비용과 시간을 획기적으로 줄일 수 있고, 객체를 통해 데이터를 관리하여 데이터를 손실 없이 관리하기에 용이하다.
클래스(Class)
클래스(Class)란 객체를 정의한 설계도 또는 틀 이라 정의할 수 있다. 즉, 클래스는 객체를 생성하는 데 사용되며, 반대로 클래스에 정의되고 설계된 내용을 그대로 생성한다.
클래스는 객체 그 자체가 아니라 단지 객체를 생성하는 사용되는 하나의 틀이라는 것이다.
객체(Object)
모든 실재하는 어떤 대상을 프로그래밍 언어에서는 객체(Object)라고 부른다.
심지어 눈에 보이지 않는 어떤 논리나 사상, 개념 같은 무형의 대상들도 객체라는 범주에 포함될 수 있다. 한마디로 객체는 우리가 보고 느끼고 인지할 수 있는 모든 것을 의미한다.
객체지향이론의 핵심 개념은 실제 세계는 이러한 객체들로 구성되어 있으며, 발생하는 모든 사건들은 이 객체들 간의 상호작용을 통해 발생한다는 전제로부터 출발한다.
객체는 크게 속성과 기능이라는 두 가지 구성요소로 이뤄져 있다. 속성과 기능은 각각 필드와 메서드로 정의되는데, 일반적으로 하나의 객체는 다양한 속성과 기능의 집합으로 이뤄져 있다. 그리고 이러한 속성과 기능은 이너클래스와 함께 객체의 멤버(member)라 부른다.
객체 생성은 new키워드를 사용하여 다음과 같이 실제 객체를 생성할 수 있다. 객체를 생성한 이후에는 포인트 연산자(.)를 통해 해당 객체의 맴버에 접근 가능하다.
클래스명 참조_변수명; // 인스턴스를 참조하기 위한 참조변수 선언
참조_변수명 = new 생성자(); // 인스턴스 생성 후, 객체의 주소를 참조 변수에 저장특정 클래스 타입의 참조 변수를 선언한다. 참조 변수가 선언되면, 이제 new 키워드와 생성자를 통해 인스턴스를 생성하여 참조 변수에 할당한다. 참조 변수는 실제 데이터 값이 아니라 실제 데이터가 저장되어 있는 힙 메모리의 주소값 을 가리킵니다.
new 키워드는 생성된 객체를 힙 메모리에 넣으라는 의미 가지고 있는데, 생성자를 통해 객체가 만들어지면 해당 객체를 힙 메모리에 넣는 역할을 한다. 이 과정을 줄여서 다음처럼 선언할 수 있다.
클래스명 참조_변수명 = new 생성자();
인스턴스(instance)
클래스를 통해 생성된 객체를 해당 클래스의 인스턴스(instance)라 부른다.
또한 클래스로 부터 객체를 만드는 과정을 인스턴스화(instantiate)라 지칭한다.
객체와 인스턴스의 차이가 무엇일까?
객체와 인스턴스는 같은 말이라 차이를 두는 것에는 큰 의미는 없다. 그럼에도 조금 엄격하게 두 용어를 구분 해보면,
객체는 모든 인스턴스를 포괄하는 넓은 의미를 가지고 있는 반면, 인스턴스는 해당 객체가 어떤 클래스로 부터 생성된 것인지를 강조 한다는 데 차이가 있다.
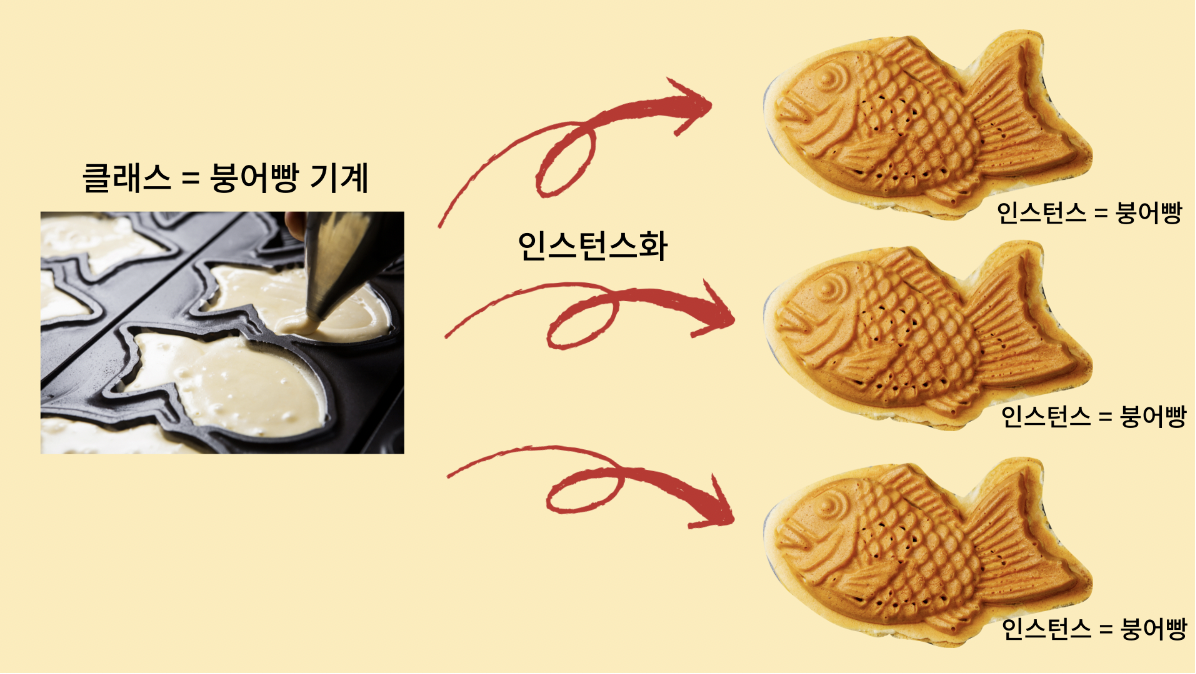
잘 만들어진 붕어빵 기계는 백 번이고, 수 천 번이고 계속해서 같은 모양의 붕어빵을 잘 만들어낼 수 있다.
이와 마찬가지로 클래스를 한번 잘 정의해 놓으면, 매번 객체를 생성할 때마다 어떻게 객체를 만들어야 할 지 더이상 고민하지 않고, 그저 클래스로부터 객체를 생성해서 사용하기만 하면 된다.
클래스의 구성요소와 기본 문법
클래스를 정의하는 방법은 'class' 키워드를 사용하여 다음과 같이 정의한다. 클래스명은 주로 대문자로 시작하는 것이 관례이다.
class Example { //클래스 정의
...
}클래스는 크게 필드(field), 메서드(method), 생성자(constructor), 이너 클래스(inner class)로 구성되어 있다.
public class ExampleClass {
int x = 10; // (1)필드
void printX() {...} // (2)메서드
ExampleClass {...} // (3)생성자
class ExampleClass2 {...} // (4)이너 클래스
}
(1) 필드 - 클래스의 속성을 나타내는 변수입니다. 자동차로 예를 들면 모델명, 컬러, 바퀴의 수 등이 포함될 수 있다
(2) 메서드 - 클래스의 기능을 나타내는 함수입니다. 자동차를 예로 들면 시동하기, 가속하기, 정지하기 등이 포함될 수 있다.
(3) 생성자 - 클래스의 객체를 생성하는 역할을 한다.
(4) 이너 클래스 - 클래스 내부의 클래스를 의미한다.
위의 구성 요소들 중 생성자를 제외한 나머지 3가지 요소를 우리는 클래스의 멤버(member)라 부른다.
이 중에서 필드와 메서드는 각각의 클래스가 가지는 속성(state)와 기능(behavior)을 대표한다. 속성과 기능은 해당 클래스와 관련된 데이터의 집합이며, 핵심적인 정보를 담고있다.
객체생성과 메모리 개념

먼저 참조 변수는 앞서 설명한대로 실제 데이터 값을 저장하는 것이 아니라 실제 데이터가 위치해있는 힙 메모리의 주소를 저장하는 변수를 의미한다.
따라서 우리가 'new' 키워드와 생성자를 통해 클래스의 객체를 생성한다는 것은 해당 객체를 힙 메모리에 넣고 그 주소값을 참조변수에 저장하는 것 이다.
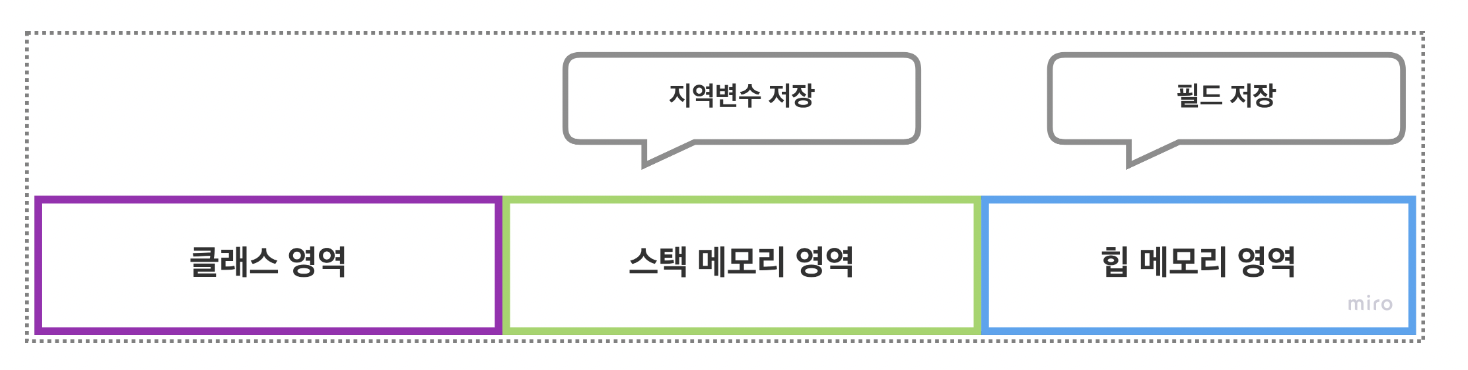
클래스 Person과 참조 변수 p는 각각 클래스 영역과 스택 영역이라는 다른 위치에 저장된다.
생성자로 만들어진 인스턴스는 힙 메모리 영역에 들어가며 객체 내부에는 클래스의 멤버들이 위치하게 된다.
메서드의 구현 코드의 위치를 보면 메서드 구현 코드는 클래스 영역에 저장되고 객체 안에서는 그 위치를 가리키고 있다.
즉 같은 클래스로 만든 모든 객체는 동일한 메서드 값을 공유하기 때문에 여러 번 같은 메서드를 선언해주는 것이 아니라 한번만 저장해두고 필요한 경우에만 클래스 영역에 정의된 메서드를 찾아 사용할 수 있는 것입니다.
생성된 객체에서 필드값은 실제 저장공간이 객체 내부에 있다.
메서드는 다른 영역에 하나만 저장해놓고 공유한다.
객체의 활용
포인트연산자(.)를 이용해 특정 인스턴스 객체의 필드와 메서드, 즉 객체의 맴버들에 접근할 수 있다. 기본적인 문법은 다음과 같다.
참조 변수명.필드명 // 필드값 불러오기
참조 변수명.메서드명() // 메서드 호출아래 Car클래스와 CarTest클래스를 생성하여 예시를 보겠다.
public class CarTest {
public static void main(String[] args) {
Car tesla = new Car("Model 3", "빨강"); // 객체 생성.
System.out.println("내 차의 모델은 " + tesla.model + "이고" + "색은 " + tesla.color + "입니다."); // 필드 호출
tesla.power(); // 메서드 호출
tesla.accelerate();
tesla.stop();
}
}
class Car {
public String model; // 필드 선언
public String color;
public Car(String model, String color) { // 인스턴스 초기화를 위한 생성자 함수.
this.model = model;
this.color = color;
}
void power() { // 메서드 선언
System.out.println("시동을 걸었습니다.");
}
void accelerate() {
System.out.println("더 빠르게!");
}
void stop(){
System.out.println("멈춰!!");
}
}
// 출력값
내 차의 모델은 Model 3이고 색은 빨강입니다.
시동을 걸었습니다.
더 빠르게!
멈춰!!예시에서 model과 color의 속성을 가지며 power(), accelerate(), stop() 기능을 가지고 있는 Car 클래스를 정의했다.
그리고 CarTest 클래스 안에서 tesla 인스턴스를 만들어 앞서 정의한 속성과 기능을 println() 메서드를 통해 출력했다.
필드(Field)
필드는 ‘클래스에 포함된 변수'를 의미하는 것으로 객체의 속성을 정의할 때 사용된다.
자바에서 변수는 크게 클래스 변수(cv, class variable), 인스턴스 변수(iv, instance variable), 지역 변수(lv, local variable)라는 세 가지로 구분할 수 있다. 이중 우리가 필드라고 부른 것은 클래스 변수와 인스턴스 변수 이다. 그리고 이 둘은 다시 static키워드의 유무로 구분할 수 있다.
좀더 구체적으로 static 키워드가 함께 선언되면 클래스 변수, 그렇지 않은 것은 인스턴스 변수 이다.
이 두가지 변수 유형에 포함되지 않고 메서드 내에 포함된 모든 변수를 지역변수라 한다.
인스턴스 변수와 클래스 변수는 클래스 영역에 있기때문에 맴버 변수 이다.
class Example { // => 클래스 영역
int instanceVariable; // 인스턴스 변수
static int classVariable; // 클래스 변수(static 변수, 공유변수)
void method() { // => 메서드 영역
int localVariable = 0; // 지역 변수. {}블록 안에서만 유효
}
}인스턴스 변수(iv)는 인스턴스가 가지는 각각의 고유한 속성을 저장하기 위한 변수로 new 생성자() 를 통해 인스턴스가 생성될때 만들어진다. 클래스를 통해 만들어진 인스턴스는 힙 메모리의 독립적인 공간에 저장되고, 동일한 클래스로부터 생성되었지만 객체의 고유한 개별성을 가진다.
클래스 변수(cv)는 독립적인 저장 공간을 가지는 인스턴스 변수와 다르게 공통된 저장공간을 공유한다. 따라서 한 클래스로부터 생성되는 모든 인스턴스 들이 특정한 값을 공유해야하는 경우에 주로 static 키워드를 사용하여 클래스 변수를 선언하게 된다.
클래스 변수는 인스턴스 변수와 달리 인스턴스를 따로 생성하지 않고도 언제라도 클래스명.클래스변수명 을 통해 사용이 가능하다.
지역변수(Iv)는 메서드 내에 선언되며 메서드 내({} 블록)에서만 사용 가능한 변수입니다. 멤버 변수와는 다르게 지역변수는 스택 메모리에 저장되어 메서드가 종료되는 것과 동시에 함께 소멸되어 더 이상 사용할 수 없게 된다.
또한 힙 메모리에 저장되는 필드 변수는 객체가 없어지지 않는 한 절대로 삭제되는 않는 반면, 스택 메모리에 저장되는 지역변수는 한동안 사용되지 않는 경우 가상 머신에 의해 자동으로 삭제된다.
필드 변수와 지역 변수의 주요한 한 가지 차이점은 초기값에 있다.
지역변수는 직접 초기화 하지 않으면 값을 출력할 때에 오류가 발생한다. 하지만 필드변수는 직접적으로 초기화 하지 않아도 강제로 초기화가 이루어 진다.
힙 메모리에는 빈 공간이 저장될수 없기 때문에 이곳에 저장되는 필드는 강제로 초기화가 되지만, 스택 메모리는 강제로 초기화 되지 않으므로 지역변수는 선언시 반드시 초기화를 해줘야한다.
static키워드
static은 클래스 맴버에 사용하는 키워드이다. static 키워드가 붙어있는 멤버를 ‘정적 멤버(static member)'라 한다.
static 키워드로 정의되어 있는 클래스 멤버들은 인스턴스의 생성 없이도 클래스명.멤버명 만으로도 사용이 가능하다.
정적 멤버도 객체를 생성한 이후 참조변수를 통해 사용이 가능하지만, 애초에 정적 멤버임을 표시하기 위해서 클래스명.멤버명 의 형태로 사용할 것을 권장한다.
static 키워드로 선언된 정적 멤버는 클래스 내부에 저장 공간을 가지고 있기 때문에 객체 생성 없이 곧바로 사용가능하다.
정적 필드는 객체 간 공유 변수의 성질이 있다. 이것은 메서드에도 동일하게 적용됩니다. 일반적인 메서드 앞에 static 키워드를 사용하면 해당 메서드는 정적 메서드가 된다. 정적 메서드도 정적 필드와 마찬가지로 클래스명만으로 바로 접근이 가능하다.
정적 메서드의 경우 인스턴스 변수 또는 인스턴스 메서드를 사용할 수 없다. 정적 메서드는 인스턴스 생성 없이 호출이 가능하기 때문에 정적 메서드가 호출되었을 때 인스턴스가 존재하지 않을 수 있기 때문이다.
static 키워드를 사용하면 모든 인스턴스에 공통적으로 적용되는 값을 공유할 수 있습니다.
결론적으로 static 키워드는 클래스의 멤버 앞에 붙일 수 있습니다. 정적 멤버의 가장 큰 특징은 인스턴스를 따로 생성하지 않아도 클래스명만으로도 변수나 메서드 호출이 가능하다.
메서드(Method)
메서드는 특정 작업을 수행하는 일련의 명령문들의 집합을 의미하며, 클래스의 기능에 해당하는 내용들을 담당한다.
메서드는 크게 머리에 해당하는 메서드 시그니처(method signature)와 몸통에 해당하는 메서드 바디(method body)로 구분할 수 있다.
public static int add(int x, int y) { // 메서드 시그니처
int result = x + y; // 메서드 바디
return result;
}메서드의 시그니처는 해당 메서드가 어떤 타입을 반환하는 가(반환 타입), 메서드 이름이 무엇(메서드명)이며 해당 작업을 수행하기 위해서 어떤 재료들이 필요한지(매개 변수)에 대한 정보를 포함한다.
메서드의 바디는 괄호({}) 안에 해당 메서드가 호출되었을 때 수행되어야하는 일련의 작업들을 표시한다. 참고로 메서드명은 관례적으로 소문자로 표시한다.
위에 예시를보면 메서드명이 add인 메서드이며 int타입의 x, y값을 받아 더한다음 결과값을 반환하는 메서드이다.
만약 메서드의 반환타입이 void가 아닌 경우에는 메서드 바디({} )안에 반드시 return 문이 존재해야 한다. 결과값은 반드시 반환타입과 일치하거나 적어도 자동 형변환이 가능한 것이어야 합니다.
void printHello() { // 반환타입이 void인 메서드
System.out.println("hello!");
}메서드 반환 타입이 void, 즉 반환값이 없는 메서드를 의미하며, 메서드는 호출되면 hellod!라는 내용을 출력하고 종료된다.
int getNumSeven() { // 매개변수가 없는 메서드
return 7;
}int 타입의 결과값을 반환하는 매개변수가 없는 메서드이다.메서드가 호출되면 그냥 숫자7을 반환하면 되기 때문에 따로 매개변수가 필요하지 않다.
Double multiply(int x, double y) { // 매개변수가 있는 메서드
double result = x * y;
return result;
}매개변수를 전달받아 반환타입이 double인 result를 반환하는 메서드이다. int와 double타입을 산술하연산하면 범위가 더 큰 타입으로 자동으로 형 변환이 이루어진다.
메서드 호출
메서드도 클래스의 멤버이므로 클래스 외부에서 메서드를 사용하기 위해서는 먼저 인스턴스를 생성해야합니다. 인스턴스를 생성한 후에 앞서 보았던 것처럼 포인트 연산자(.)를 통해 메서드를 호출할 수 있다.
하지만 클래스 내부에 있는 메서드끼리는 따로 객체를 생성하지 않고도 서로를 호출할 수 있다.
메서드 호출 시 괄호() 안에 넣어주는 입력 값을 우리는 ‘인자(argument)’라고 하는데, 인자의 개수와 순서는 반드시 메서드를 정의할 때 선언된 매개변수와 일치되어야 한다. 인자의 타입 또한 매개변수의 그것과 일치하거나 자동 형변환이 가능한 것이어야 한다.
메서드 오버로딩
하나의 클래스 안에 같은 이름의 메서드를 여러개 정의하는 것을 의미한다.
메서는 오버로딩은 메서드의 이름 또는 매개변수의 타입이 다르면 다른 메서드라고 인식하는 자바 가상머신의 기능과 관계있다.
무조건 같은 메서드명을 사용한다고해서 오버로딩이 되는것이 아니다. 오버로딩이 성립하기 위해서는 크데 두가지 조건이 성립되어야한다.
- 메서드의 이름이 같아야한다.
- 매개변수의 개수나 타입이 다르게 정의되어야한다.
참고로 반환 타입은 오버로딩이 성립하는 데에 영향을 주지 못합니다.
public class Overloading {
public static void main(String[] args) {
Shape s = new Shape(); // 객체 생성
s.area(); // 메서드 호출
s.area(5);
s.area(10,10);
s.area(6.0, 12.0);
}
}
class Shape {
public void area() { // 메서드 오버로딩. 같은 이름의 메서드 4개.
System.out.println("넓이");
}
public void area(int r) {
System.out.println("원 넓이 = " + 3.14 * r * r);
}
public void area(int w, int l) {
System.out.println("직사각형 넓이 = " + w * l);
}
public void area(double b, double h) {
System.out.println("삼각형 넓이 = " + 0.5 * b * h);
}
}
//출력값
넓이
원 넓이 = 78.5
직사각형 넓이 = 100
삼각형 넓이 = 36.0위에 예시를 보면 모든 메서드들이 area()라는 메서드명을 가지고 있음에도 불구하고 각기 다른 출력값을 리턴하는 것을 확인할 수 있다.
오버로딩의 장점이 무엇일까?
가장 큰 장점은 하나의 메서드로 여러 경우의 수를 해결할 수 있다는 것이다.
오버로딩의 대표적인 예시로 println() 메서드가 있습니다. 지금까지 우리가 println() 메서드를 사용했을 때 아무 값이나 괄호()안에 인자로 넣어서 사용하는데 문제가 없었지만, 사실 그 내부를 살펴보면 매개변수의 타입에 따라서 호출되는 println 메서드가 달라진다는 사실을 알 수 있다.
'Java' 카테고리의 다른 글
| Java 상속, 캡슐화 (0) | 2022.09.07 |
|---|---|
| Java 생성자, 내부 클래스 (1) | 2022.09.05 |
| Java 배열(Array) (0) | 2022.09.02 |
| Java 제어문 (0) | 2022.09.01 |
| Java 기초 (0) | 2022.08.31 |



